Process hangover: L1 responders aren’t able to resolve issues
NOCs used to be the command center for technology issues. They functioned like a brain, sending out signals to relevant appendages. Issue with networking? Route to networking. Issue with security? Route to security. The NOC’s central function was to involve the correct SME to resolve an issue. This meant digging through spreadsheets (and sometimes physical contact books!) to figure out who was responsible for what.
When everything was on premise and in person, this made sense. There were fewer services, and incidents could be neatly separated by departments. If the database was having an issue, you could call up the database on-call responder. The responder (who would likely be in office or close enough to respond in person) could then go to the datacenter and take a look.
Now, in the remote work, cloud era, where organizations have hundreds or thousands of services maintained by dozens or even hundreds of teams spread across the globe, the rolodex method has outlived its purpose. It’s next to impossible to maintain accurate spreadsheets to know which teams are responsible for which services. And, as the organization changes, records grow stale quickly. Services can move between teams. Teams change as people move between them, or leave/join the company. Now, an L1 responder has to work too hard to identify the right person in an efficient and timely manner.
Organizations need a way to remove these manual steps to find the right person and route incidents directly to SMEs who can jump in to respond to any issues. This can happen in a variety of ways. For some organizations, a DevOps service ownership model is the right path forward. Those who write the code are assigned to respond and fix the service during an incident. The alert is routed directly to the on-call person on the development team that supports the service, and the SME takes it from there.
For other organizations, it might make sense to have a hybrid approach where L1 responders serve as the first line of defense before escalating to distributed, on-cal teams for their services. L1 responders shouldn’t be a routing center that connects the issue with another team. Instead, they should be empowered to resolve an incident themselves. You can set up your L1 responders to be more effective by enabling them with the ability to both troubleshoot and selectively resolve incidents. Access to automation and resources like runbooks can empower L1 responders to help accelerate the diagnosis and remediation process, oftentimes without needing to disrupt the subject matter experts that are in charge of X service via an escalation. By putting automation in the hands of L1 responders, organizations can avoid unnecessary escalations and empower L1s to resolve issues faster.
Process hangover: Major incidents aren’t called or are called too late
We’ve heard it before: time is money. And when NOCs were the primary method of ensuring incidents were responded to, they had an additional responsibility. An NOC needed to ensure that resources were well managed. This meant no unnecessary personnel responding to problems. NOCs often took the blame if they called a major incident too soon and interrupted people for a minute problem. These disruptions took SMEs away from their work innovating. So it was crucial for NOC responders to only call major incidents when it was clear there was a much bigger issue at play.
But now, time isn’t money, uptime is money. The cost of a major incident that’s flown under the radar is larger than the cost of tagging in some extra help. Imagine you’re an online retailer and your shopping cart function is down. Every minute your customers can’t add items to their cart, you’re losing hundreds of thousands of dollars. Plus, customer expectations have increased over the last few years. Customers expect that their app, tool, platform, streaming service, etc. works without interruption. And it erodes customer trust when it doesn’t. In fact, according to PWC, 1 in 3 customers would stop doing business with a brand they loved after one bad experience.
Organizations need to call major incidents sooner to mitigate customer impact. Yes, this may mean waking someone unnecessarily once in a while. But, that’s far less likely with service ownership. SMEs responsible for a service have a better understanding of when to call a major incident than an L1 responder would. So there are fewer false alarms.
Process hangover: Come-and-go war rooms
NOCs often serve as the communication hub for a major incident. This helps responders working to resolve an issue keep on task. Back when many companies had everything (and everyone) on-premise, there was a war room. People came there and the NOC coordinator kept everyone up to date. Now, with distributed teams and systems, physical war rooms are a thing of the past. Many companies instead have virtual war rooms with a video conferencing bridge or chat channel that remains open during an incident.
Other stakeholders may want to treat this war room like a physical one, dropping in as they please. But, in this virtual world, this means that these stakeholders are asking the incident responders questions. This delays the resolution. Companies with come-and-go virtual war rooms may experience more miscommunications and frustration. Responders feel frustrated by interruptions and stakeholders feel frustrated with the lack of communication.
One way to mitigate this is to close the war room to non-participants. If someone isn’t a part of the incident response team, they don’t need access to the response team’s virtual war room. Instead, what they need is an internal liaison. This is a designated communicator from the incident response team.
The internal communication liaison consolidates incident information and relays it to relevant stakeholders. To make this easier, communication liaisons can use status update notification templates. These templates dictate how to craft communications for a specific audience. They ensure that stakeholders receive any information necessary to make decisions. And no responders have to stop working on the incident at hand to share updates.
Hangovers aren’t fun, but they always end
NOCs are a tried and true way of managing incidents for many organizations. But NOC methods become out of date when moving into this era of digital transformation. Seamless communication and rapid response are key to preserving customer trust. Looking forward, teams will involve SMEs immediately and call major incidents sooner rather than later. They’ll also communicate with key stakeholders throughout an incident while setting boundaries.
And often teams need a digital operations platform to help support this transition. PagerDuty allows teams to bring major incident best practices to their organization, resolving critical incidents faster and preventing future occurrences. Try us for free for 14 days.
A Deep-Dive Into PagerDuty’s New Incident Workflows
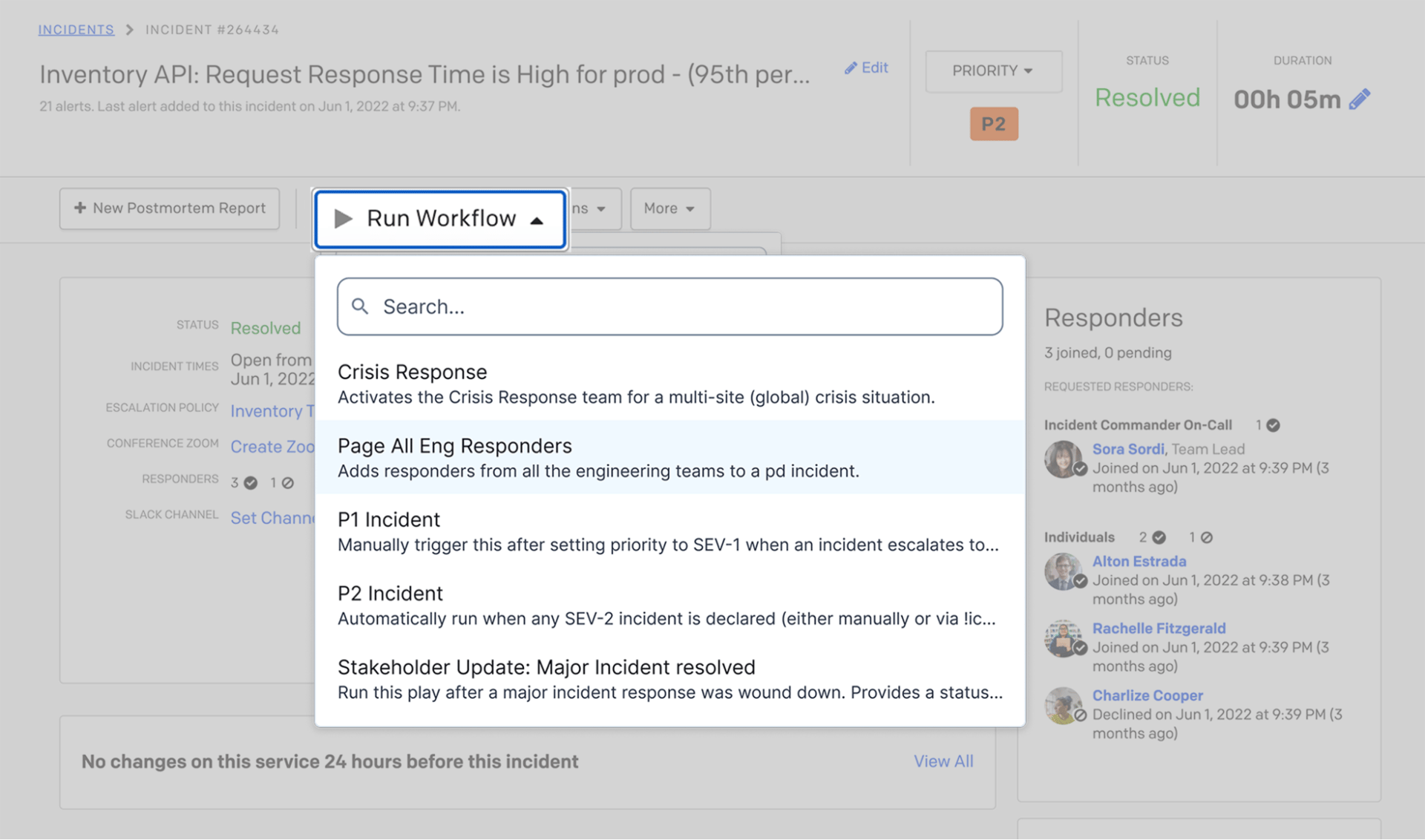
Earlier this month, PagerDuty announced several product advancements to help customers improve team efficiency and productivity. One of the most highly anticipated announcements is the introduction of Incident Workflows to automate incident response. This feature starts rolling out to Early Access customers today.
Think about all of the manual steps in your incident response process. High-priority incidents impacting multiple teams can be chaotic when getting all hands on deck to resolve the issue as quickly as possible. Remembering to make sure X, Y, Z are done every time adds more cognitive load to an already stressful process. These repeatable, manual tasks are perfect candidates for automation.
The more that automation can remove toil and take care of rote tasks in incident response, the faster teams can focus on problem identification and resolution. And the faster they can resolve an incident, the sooner they can get back to building new products and services.
Incident Workflows automatically orchestrate the actions you already know you’ll need to take based on the type of incident at hand. Serving as an upgrade from Response Plays, now you can use a no-code/low-code builder to create customizable incident workflows that will reduce the manual work required to escalate, mobilize, and coordinate the right incident response for any use case. You can automatically trigger an orchestrated response using if-this-then-that logic to sequence common incident actions, such as adding a responder, subscribing stakeholders, or spinning up a conference bridge.
Let’s take a closer look at the functionality that makes Incident Workflows so powerful.
Conditional Triggers
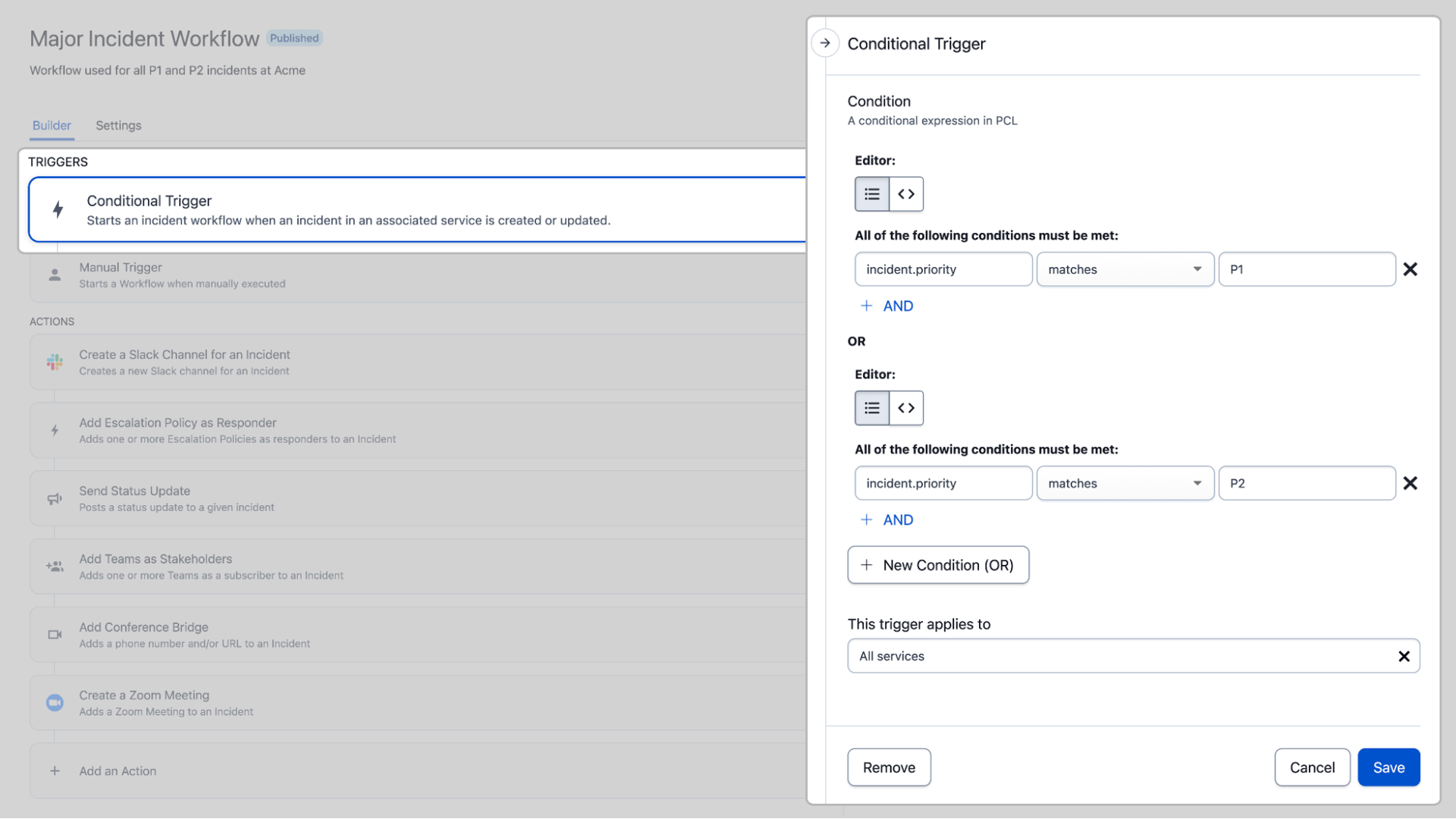
Different incident types require different remediation steps. Conditional triggers allow you to address these differentiated needs by creating logic to kick off a workflow when criteria for certain incident fields are met–like changes to urgency, priority, or status. If an incident gets upgraded from a P3 to a P1, for example, you can set up conditional triggers to kick off a specialized workflow for major incidents. And for the users who would like to double down on automation, you could even set priority using Event Orchestration and have your Incident Workflow pick up that priority change as a trigger for the major incident workflow.
You can also utilize manual triggers that allow a responder to start a workflow directly from the incident details page. When a manual trigger is added, Incident Workflows can be triggered from the PagerDuty web app, mobile app, Slack, Microsoft Teams, or directly through the API.
Enhanced CollabOps Actions
Save time setting up collaboration channels by configuring your workflow to do it for you. Use workflow actions to spin up a Zoom conference bridge or create a per-incident Slack channel that includes all incident responders and incident updates. Comparable functionality for creating a MS Teams Meeting will be coming soon. As mentioned previously, you can also set up manual triggers within Slack or MS Teams if your team finds it useful.
Easy Communications
Communicating to internal and external stakeholders in a timely and transparent way is essential to effective incident response. As my colleague, Hannah Culver, explained, having a prepared business response plan in place can help internal cross-functional teams work better together, while also helping customer-facing teams preserve customer trust through proactive communications. Incident Workflows make this piece of the puzzle easier by allowing users to automate adding responders to the incident, subscribing stakeholders, and posting status updates, so you can keep everyone who needs to know about the incident informed in real time.
End-to-End Automation on a Unified Platform
Incident Workflows were built to pair with other automation features on the PagerDuty platform to help teams resolve faster and minimize impact to revenue. For example, Event Orchestration can simultaneously change priority to automatically trigger an Incident Workflow, while also kicking off automated diagnostics via Automation Actions so that the script is already run by the time the right responders are called and get to the incident-specific Slack channel that the Incident Workflow has spun up.
Conclusion
During Incident Response, responders should be free to focus on their core responsibility – resolving the incident. Incident Workflows give them the gift of being able to automate those other essential, yet tedious tasks in a standardized, repeatable way. By standardizing your incident response processes, you can ensure the right actions are taken across teams to reduce your time to incident resolution. Given that Incident Workflows are already included in Business and Digital Operations plans, it makes sense to utilize this great new functionality at no additional cost. Why piece together your tech, when you can achieve end-to-end incident response all in one place? Your management team asking about tool consolidation will certainly appreciate it.
This is just the first step in PagerDuty’s journey towards offering more extensibility for our customers to configure responses for their unique use cases. To learn more about Incident Workflows, check out our KB article and sign up for Early Access.
4 New Product Announcements to Help Teams Do More with Less
Incidents are costly. It’s not just revenue that takes a hit every time you have an outage–brand reputation and client satisfaction are also on the line. To protect current and future revenue, companies have to deliver on customer expectations. Innovation alone is no longer enough: digital experiences must also be fast, flawless, and highly available. This means teams have to get more proactive with real-time, unplanned work. Only then can they account for the 1 in 3 customers who would stop doing business with a brand they loved after one bad experience (PWC).
If that wasn’t hard enough, you now need to do all of this with less. 98% of CEOs are preparing for a recession in the next 12 to 18 months (The Conference Board). Teams have to get more efficient, because costs are high, resources are low, and skills are scarce. Teams can’t afford to work harder–they have to work smarter. Instead of five tools to manage event correlation, diagnostics capture, incident workflows, incident communications, and customer status pages, you need one solution for end-to-end incident response.
Today, PagerDuty is announcing new ways to drive efficiency across your digital operations. With expanded noise reduction, workflow automation, and stakeholder communication capabilities, the PagerDuty Operations Cloud is the only solution on the market that delivers end-to-end automated incident response from ingest to resolution. If you’ve only been using the platform for on-call and alerting, it’s time to consider how you could achieve your cost-optimization goals with PagerDuty.
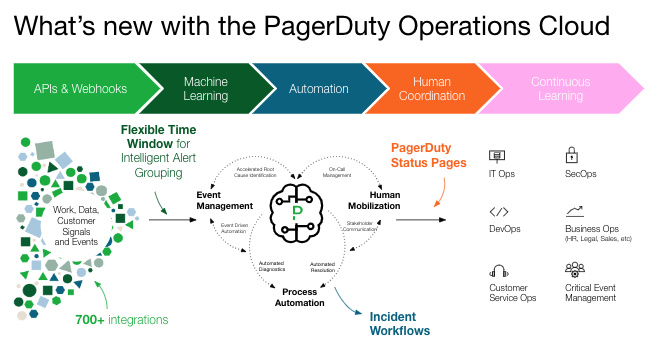
Earlier this year, you heard about how the PagerDuty Operations Cloud is revolutionizing operations for a world of digital everything. Over 21,000 organizations rely on the PagerDuty platform to react, respond, and resolve issues quickly in real-time by:
– Using APIs and webhooks to understand what’s happening in your environment with over 700 integrations
– Applying machine learning to help reduce the noise to signal ratio and keep teams focused on what’s important
– Automating repetitive, manual processes to deflect manual work and avoid costly escalations
– Mobilizing business-wide response for faster resolution and better customer experiences
– Learning continuously to better anticipate and prevent repeat issues
In this blog, we’ll highlight four of the key innovations coming to the PagerDuty Operations Cloud, before summarizing the full list of new capabilities.
Design and automate Incident Workflows to reduce manual toil and save time spent per incident
The more that automation can remove toil and take care of rote tasks in incident response, the faster teams can focus on problem identification and resolution. And the faster they can resolve an incident, the sooner they can get back to building new products and services.
Today we’re thrilled to announce that Incident Workflows is entering Early Access for PagerDuty Business and Digital Operations customers soon. Incident Workflows give teams more flexibility and control over what types of responses they want to configure for different types of incidents. This takes Response Plays to a whole different level by offering full end-to-end workflow automation, tightly integrated into ChatOps and the rest of the incident response platform. This is just the first step in our journey towards offering more extensibility for our customers to configure responses for their specific use cases.
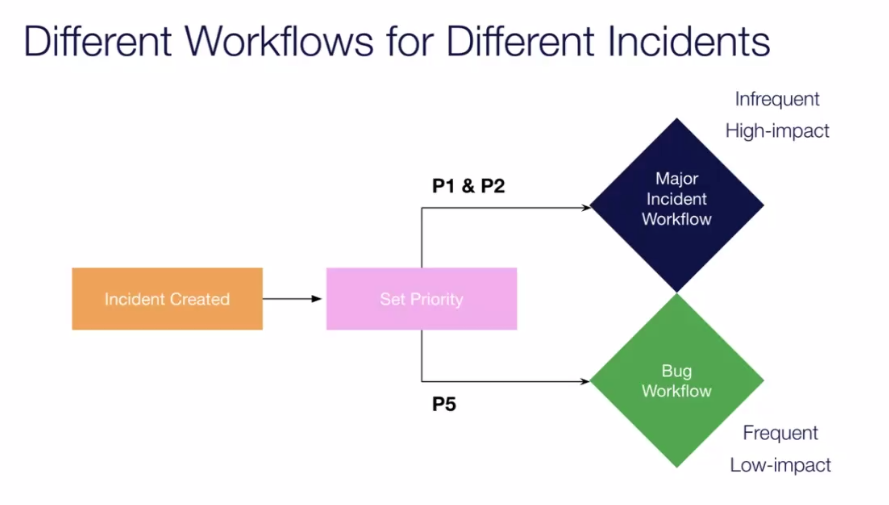
Users can rapidly design incident process automation via an easy-to-use, no-code interface that configures workflows that can automatically trigger based on changes in urgency, priority, or severity. For example, you can customize a major incident workflow that automatically opens a conference bridge, adds responders, and starts an incident-specific Slack channel to keep everyone in sync.
You can also design a separate workflow for handling smaller bugs and routing them into a backlog for a team to look at later. This takes the cognitive load off the response team and makes incident response processes smoother and more consistent.
Proactively manage customer relationships with real-time updates via PagerDuty Status Pages
The most important stakeholder in incident response is your customer. Mishandling external stakeholder communication around operational updates erodes trust and harms customer relationships. Without timely updates via a status page, support teams are flooded, which drives up costs.
Today, we’re happy to announce the Early Access of PagerDuty Status Page. One of our top-requested features, PagerDuty Status Page will keep your customers informed about critical operational updates happening in your system. It also saves time, reduces support volumes, and avoids context switching with a single source of truth without requiring additional third-party infrastructure. Providing this level of visibility helps to maintain trust and transparency with valued accounts and external stakeholders.
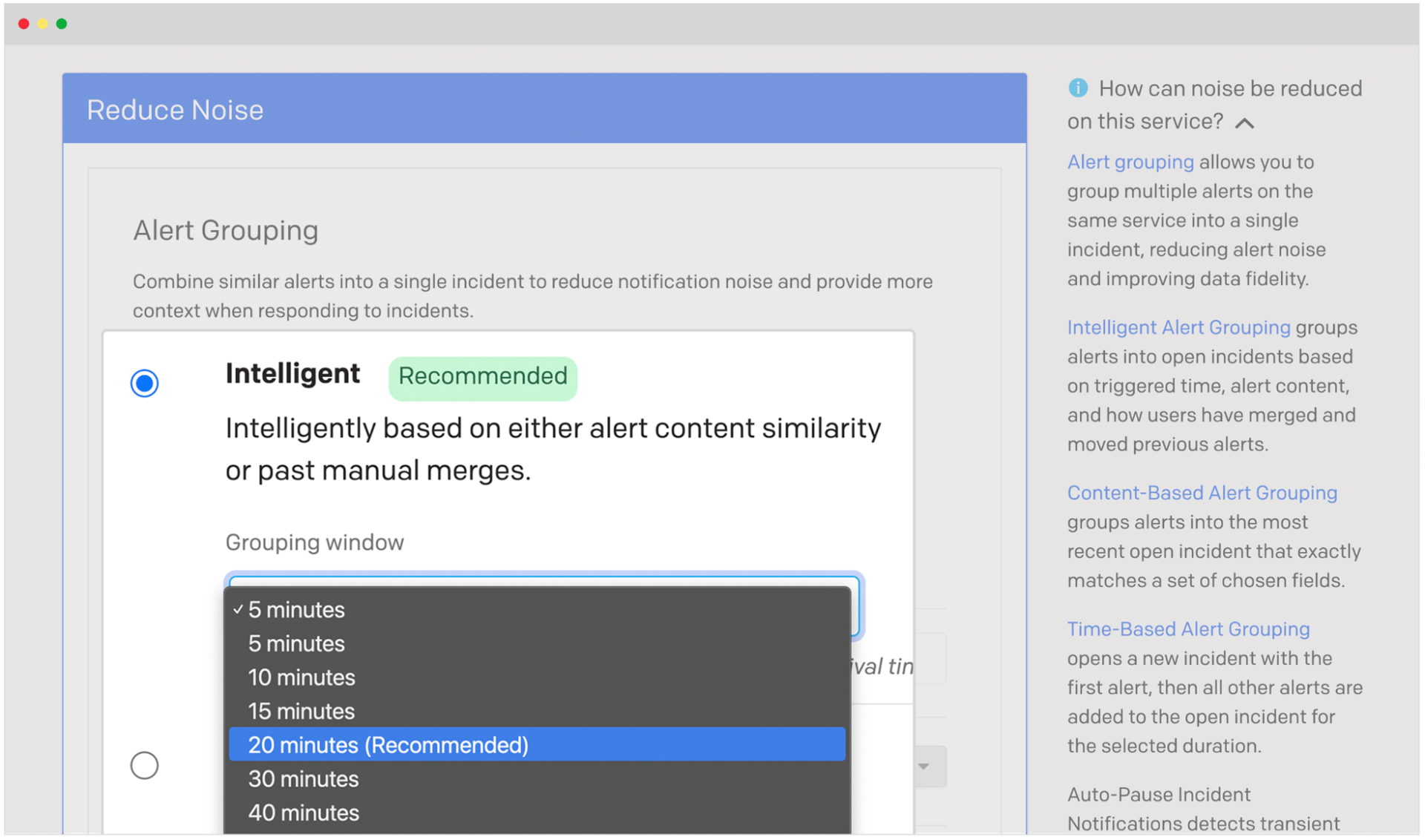
More focused engineering time and fewer incidents with more flexible Intelligent Alert Grouping
Teams can’t focus on triage if they’re bombarded by an alert storm. PagerDuty has seen event data grow at nearly 3x the rate of users, outpacing technical teams’ ability to manually process and correlate it all across silos.
We’re happy to announce a new enhancement to our AIOps-powered noise reduction suite: Flexible time windows for Intelligent Alert Grouping. A configurable time interval provides teams with more flexibility and granularity when tuning system noise on services in their specific environment. The feature is currently in Early Access for Event Intelligence and Digital Operations customers. Customers in the Early Access program saw up to a 45% increase in the average compression rate on their noisiest services in a matter of weeks.
The machine learning-driven engine will also surface recommendations for optimal time windows based on historical analysis of time between alerts. This helps teams not only maximize noise compression and minimize manual alerting grouping, but also reduce the guesswork needed by the operator and improve efficiencies.
Try Event Intelligence today: If you’re an existing PagerDuty Incident Response customer, you can start a 30-day free trial of Event Intelligence from the PagerDuty product under Account Settings. If you’re new to PagerDuty, simply start a free 14-day trial to get started today.
Higher uptime with fewer communication snafus with best practices for streamlined communication and stakeholder management
True to our DevOps roots, PagerDuty aims to pay it forward to our customers and the industry by sharing best practices. That’s why we’ve invested in Ops Guides for anything from Service Ownership to Business Response.
We’re thrilled to announce that we have updated the Incident Response Ops Guide with new learnings that we’ve codified from our own incident response experiences. We’ve now expanded the section about communications and how to streamline stakeholder management during incident response.
When the wrong people are tasked with an urgent, unplanned issue, escalations will drive up the resolution time and cost. When critical stakeholders and customer service are not informed, customer experience is put at risk. New updates across the Incident Response and key partner integrations help to streamline incident response to make sure all teams have the information when and where they need it to drive to next best action.
Custom Fields on Incidents: Populate custom fields on incidents to provide responders with more contextual data for faster triage and resolution. This feature is planned for Early Access in early 2023. Sign up for early access now.
Microsoft Teams: Coming soon for general availability, the integration will feature additional incident management actions, including: changing priority, reassigning, adding responders, escalating, and performing PagerDuty Automation Actions. Learn more.
Updates to Status Update Notification Templates: Teams can now use flexible templates to format the content and context they need for better standardized internal communications during incident response. The Rich Text Editing functionality is generally available (Learn more), while the templates functionality recently entered Early Access. Sign up for early access now.
PagerDuty for ServiceNow CSM: Agents using PagerDuty Customer Service Operations now have a direct line of escalation and communication with engineering on incidents in PagerDuty from the application where they work. General availability is coming soon. Learn more.
Mobile Updates: A new home screen experience in Early Access that streamlines the navigation to help responders access their most important incidents. Also, mobile service maintenance windows are now generally available. Temporarily disables a service, including its integrations, for a set period of time while it is in maintenance mode, right from the mobile app. Learn more.
But wait, there’s more:
More Automation: Automation has the added benefit of distributing expertise and scaling processes to avoid overloading contributors with unplanned work and constant disruptions. Codifying and distributing subject matter expertise in the form of runbooks reduces the number of escalations required, minimizing the total number of people needed to triage, diagnose, and resolve incidents. That’s why we’ve been introducing more integrations both across our automation products and other products in the portfolio. Learn more about PagerDuty’s Process Automation portfolio here.
Automation Actions to Runbook Automation Integration: Now generally available, Customers can now seamlessly connect to their production environments and implement diagnostic and remediation jobs in the cloud. Learn more.
Automation Actions in CSOps for Zendesk: Now generally available, agents are now empowered to validate customer-impacting issues and by running automated actions directly from the PagerDuty app in Zendesk. This will reduce resolution time, as well as the number of incidents escalated to the back-end teams.
More Enhancements to Access Controls and Analytics:
More than 700 integration partners: With 80+ new integration partners introduced this year, PagerDuty snaps seamlessly into any stack. Learn more about our integration partners.
Webhooks v3: Managing webhook integrations is easier than ever. Generally available Webhooks v.3-based integrations will be visible and editable under the Service Directory UI under the Integrations tab.
API Scopes: Securing access to PagerDuty resources is becoming more granular, so you can grant the right level of access for every use case. Planned for Early Access, Scoped API access provides more flexibility with application credentials that control access and available actions on PagerDuty resources, such as account level access credentials with differentiated read-only versus read and write permissions on PagerDuty Incidents.
Updates to Login experience: Planned for Early Access, this feature provides a single, streamlined login experience for PagerDuty no matter where you’re using it: web, mobile, Slack integration. Keep an eye out for this new experience on mobile and web later this year.
Updates to Service Performance Report & Incident Activity Report: Surface actionable insights and opportunities for continuous improvement with new reports featuring new visualizations, more interactivity, intuitive drill-down capabilities, and additional filtering options. These reports are currently in Early Access for Digital Operations and Analytics customers. If you are a Professional or Business Incident Response customer, reach out to your account team to try this out for your team.
We are happy to announce that Webiscope is now part of Aman Group. We look forward giving our customers and partners greater value with more complete solutions and outstanding service.
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Strictly Necessary Cookies
Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.