
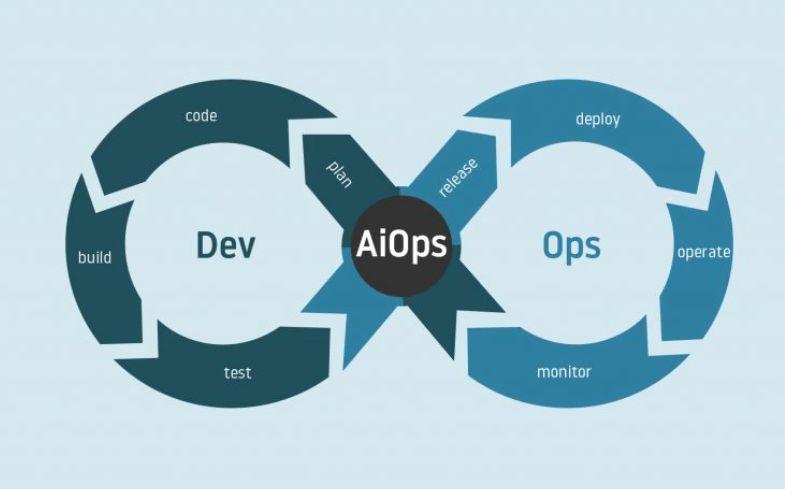
Some frameworks are for multiple teams that work separately, and this can increase risks and delays. To keep up with growing demands and avoid delays, we want to get rid of closed-off siloes. Under the DevOps model, we can merge two or more teams and focus on continuous integration and deployment, making communication better, deployment faster, and security – unbreakable. If you’re using Agile software development, DevOps is complimentary.
We’ve been using DevOps in conventional software development for a while now, but we can also use it for machine learning and artificial intelligence.
Why do we need DevOps? What’s the reason behind tiering Machine Learning and Artificial Intelligence on top of DevOps? What’s the difference between ML Ops and AI Ops? Keep reading to find out.
What is MLOps?
Many industries integrate machine learning systems into their existing products and services because ML can be good for the bottom line, and it can sharpen your competitive edge.
The problem is that machine learning processes are complicated and often require a great deal of time and resources. To avoid overspending, companies need a framework that unifies the development and deployment of ML systems. MLOps is that framework. It standardizes and streamlines the continuous delivery of ML models into productions.
Before we explore why we need to use MLOps, let’s first look at the Machine Learning modeling lifecycle to understand what the focus is.
Learn more
MLOps: What It Is, Why it Matters, and How To Implement It (from a Data Scientist Perspective)
Lifecycle of a machine learning model
ML projects start with defining a business use case. Once the use case is defined, the following steps are taken to deploy a machine learning solution into production:
- Data Extraction – Integrating data from various sources
- Exploratory Data Analysis – Understanding underlying data and its properties
- Data Preparation – Curating data for successful execution of an ML solution
- Create ML Model/Solution – Creating and training ML model using ML algorithms
- Model Evaluation and Validation – Computing model on test data set and validate the performance
- Model Deployment – Deploying ML models in production
Building and processing ML systems is a manual process, and managing such systems at scale isn’t easy. Many teams struggle with the traditional manual way of deploying and managing ML solutions.
Read also
Developing AI/ML Projects for Business – Best Practices
The Life Cycle of a Machine Learning Project: What Are the Stages?
ML tiered on DevOps – overcoming challenges
To solve issues with manual implementation and deployment of machine learning systems, teams need to adopt modern practices that make it easier to create and deploy enterprise applications efficiently.
MLOps leverages the same principle as DevOps, but with an extra layer of ML model/system.
Source: Nvidia
“The modeling code, dependencies, and any other runtime requirements can be packaged to implement reproducible ML. Reproducible ML will help reduce the costs of packaging and maintaining model versions (giving you the power to answer the question about the state of any model in its history). Additionally, since it has been packaged, it will be much easier to deploy at scale. This step of reproducibility provides and is one of several key steps in the MLOps journey. – Neal Analytics
The traditional way of delivering ML Systems is common in many businesses, especially when they are just starting out with ML. Manual implementation and deployment is enough when models are rarely changed. A model might fail when applied to real-world data as it fails to adapt to changes in the environment or changes in the data.
MLOps toolset
MLOps frameworks provide a single place to deploy, manage and monitor all your models. Overall, these tools simplify the complex process and save a great deal of time. There are several tools available in the market and provide relatively similar services:
- Version Control – Keeping track of any changes in datasets, features, and their transformation.
- Track model training – Monitoring performance of models in training
- Hyperparameter tuning – Train model using a set of optimal hyperparameters automatically.
- Model deployment – Deploying machine learning model into production. check
- Model monitoring – Tracking and governing machine learning models deployed into production
Explore more tools
While choosing any MLOps Tools, the above features are worth considering before you choose. Enterprises might also be interested in the providers where they allow free trials. Let’s have a look at a few MLOps tools:
- Amazon Sage Maker – “Amazon SageMaker helps data scientists and developers to prepare, build, train, and deploy high-quality machine learning (ML) models quickly by bringing together a broad set of capabilities purpose-built for ML.”
It accelerates the deployment process by providing Autopilot that can select the best algorithm for the prediction, and can automatically build, train, and tune models.

- neptune.ai – “Neptune helps in maintaining model building metadata in one place. Log, store, display, organize, compare, and query all your MLOps metadata. It’s focused on eperiment tracking and model registry built for research and production teams that run a lot of experiments.”
Neptune focuses on logging and storing of ML Metadata, which makes it easier to query the data to analyse later.
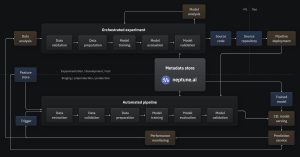
Source: Metadata Store
Neptune has categorized ML metadata into three different areas:
- Experiment and model training data – This allows users to log different metrics, hyperparameters, learning curves, predictions, diagnostic charts etc.
- Artifact metadata – This contains information about data such as path to dataset, features details, size, last updated timestamp, dataset preview etc.
- Model metadata – Model metadata contains information such as who created or trained the model, links to training and experiments done as part of modelling, Multiple datasets details etc.
The above captured data later can be used for:
- Experiment tracking – Using Neptune, the team can have a holistic view of ML experiments run by different team members. The team can easily maintain and display various metrics which help them to compare different ML experiments performance.
- Model registry – Model registry helps users to know the ML package structure, details about who created the model and when etc. The teams can easily keep track of any changes in sources, datasets and configurations etc. Neptune lets you version, display, and query most of the metadata produced during model building.
Neptune provides an easy to use dashboard display where users can easily sort, filter and query the data. It lets developers focus on model building and takes care of all the bookkeeping.
See an example dashboard here.
- DataRobot – “DataRobot MLOps provides a center of excellence for your production AI. This gives you a single place to deploy, monitor, manage, and govern all your models in production, regardless of how they were created or when and where they were deployed.”
In DataRobot, users can import models built using different languages and on other available ML platforms. Models are then tested and deployed on leading ML execution environments. DataRobot monitors service health, data drift, and accuracy using reports and alerts systems.
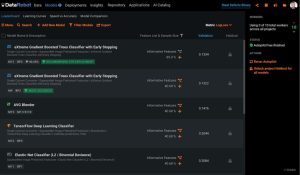
Source: Datarobot
- MLflow – “MLflow is an open-source platform to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry.”
MLflow has four main components:
- MLflow Tracking – ML Flow tracking component is organized around the concept of code execution. Each record of execution contains information, like code version, start and end time, code source, input parameters, performance metrics, and output file artifacts.
- MLflow projects –MLflow projects provide a convenient way to package machine learning code. Each project is a simple repository with multiple files and properties to run the project, such as Project Name, Entry – Points and the environment, library dependencies, etc.
- MLflow models – Mlflow format defines a standard format that lets you save a model in different flavors, such as python-function, PyTorch, sklearn, and it can be used by different platforms without much trouble at all.
- MLflow registry – MLflow Model Registry is a centralized place to collaboratively manage the lifecycle of an MLflow Model. It has a set of APIs and UI to register a model, monitor the versioning and stage transition. Developers can easily annotate these models by providing descriptions and any relevant information that can be useful for the team.
With the help of these components, teams can keep track of experiments and follow a standard way to package and deploy models. This makes it easy to produce reusable code. MLflow offers a centralized place to manage the full lifecycle of a model.

Source: Medium
- Kubeflow – “The Kubeflow project is dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable. Our goal is not to recreate other services, but to provide a straightforward way to deploy best-of-breed open-source systems for ML to diverse infrastructures. Anywhere you are running Kubernetes, you should be able to run Kubeflow.”
Kubeflow is a platform that helps to tier the ML components on Kubernetes. 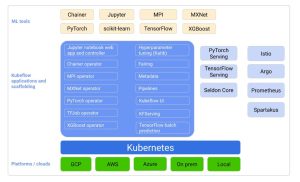
Conceptual diagram of Kubeflow
Kubeflow provides many components, and these components can be used as a standalone service or combined –
- Notebook Servers – Kubeflow notebooks help in integrating with other components easily and are easy to share as users can create notebook containers or pods directly in the cluster.
- Pipelines – The Kubeflow pipeline platform consists of a UI to manage and track experiments. With the help of pipelines, users can schedule multistep ML workflows and Python support to manipulate pipelines and workflows.
- KFServing – KFServing provides serverless inferencing on Kubernetes and encapsulates the complex processes from users by handling them automatically.
- Katib – Katib helps to tune hyperparameters of applications written in any programming language. It’s an automated process and runs several training jobs within each tuning. It supports ML frameworks such as PyTorch, XGBoost, TensorFlow, etc.
- Training Operators – Kubeflow supports distributed training of machine learning models using different frameworks such as TensorFlow, PyTorch, MXNet, and MPI.
- Multi-Tenancy – Kubeflow supports a sharable resource pool across different teams while keeping their individual work secure.
- Azure ML – “Accelerate time to market with industry-leading MLOps—machine learning operations, or DevOps for machine learning. Innovate on a secure, trusted platform, designed for responsible machine learning.”
Source: Azure
Azure ML is a cloud-based service for creating and managing machine learning model flow. Azure ML combined with Azure DevOps help implement continuous integration (CI), continuous delivery (CD), and a retraining pipeline for an AI application.
A typical Azure MLOps architecture can combine components such as Azure ML, Azure pipelines, Container registry, Container Instances, Kubernetes, or Application Performance Insights.
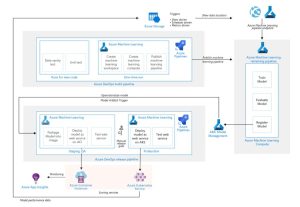
Source: Microsoft Documentations
AIOps
According to Gartner, the average enterprise IT infrastructure generates 2 to 3 times more IT operations data every year. Traditional IT management solutions won’t be able to handle volumes this large and resolve the issues properly.
Enterprises need a solution that’s automated and can alert the IT staff when there’s a significant risk. A system that can tell them what’s wrong, and resolve repetitive issues by itself as well, rather than a staff monitoring the process manually.
“AIOps combines big data and machine learning to automate IT operations processes, including event correlation, anomaly detection, and causality determination.”
With the help of AIOps, enterprises can design a solution that can correlate data across different environments. A solution that can provide real-time insight and predictive analysis to IT operations teams, helping IT teams respond to issues efficiently and meet user expectations.
Gartner predicts that for large enterprises, exclusive use of AIOps and digital experience monitoring tools to monitor applications and infrastructure will rise from 5% in 2018 to 30% in 2023.
Core element of AIOps
The definition of AIOps is dynamic, as each enterprise has different needs and accordingly implements AIOps solutions. The focus of AI solutions is to spot and react to real-time issues efficiently. Some core elements of AIOps can help an enterprise to implement AI solutions in IT operations.
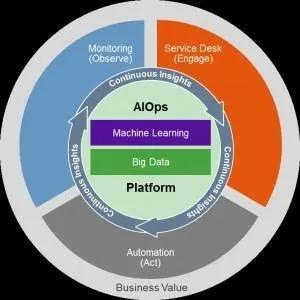
- Machine Learning – AIOps or IT Analytics is about finding patterns. With the help of machine learning, we can apply the computational power of machines to discover these patterns in IT data.
- Anomaly detection – Any changes in usual system behavior can lead to downtime, a non-responsive system, and a bad customer experience. With AIOps, it’s possible to detect any kind of unusual behaviors or activities.
- Predictive insights – AIOps introduces predictability in IT operations. It can help IT staff to be proactive in capturing any problems before they occur, and it will eventually reduce the number of service desk tickets.
- Automated root cause analysis – Driving insights alone is not enough. The enterprise or the IT team should be able to take action as well. In the traditional management environment, IT staff would monitor the systems and take steps as and when required. Due to the increasing volume of IT infrastructure issues, it would be difficult for the staff to manage and resolve the issue on time. It takes a great amount of time to analyze the root cause when multiple systems are involved. With AIOps, the root cause can be done in the background automatically.
AI tiered on DevOps
“AppDynamics surveyed 6,000 global IT leaders about application performance monitoring and AIOps.”
Artificial Intelligence for IT Operations and Dev Ops are two independent functions but, when combined, they can help to enhance the functionalities of systems. Managing a DevOps environment can be complex. Imagine going through tons of data to search for a cause that triggered an event. The teams will end up investing for hours. Many issues might be known, and some might be new or relative to previous events. Such events can be identified and resolved automatically.
DevOps is a business approach to deliver services and products to the client/market, and AI can help in streamlining testing, coding, releasing, and monitoring products with precision and efficiency.
Source: Data science Aero
“IDC predicts the global market for custom application development services is forecast to grow from $47B in 2018 to more than $61B in 2023, attaining a 5.3% Compound Annual Growth Rate (CAGR) in five years.” With these increasing demands, it will be impossible to fulfil the requirements with traditional IT Ops or development management.
AI tiered on DevOps will take traditional development management to another level by improving accuracy, quality, and reliability. According to Forbes, “Auto suggesting code segments, improving software quality assurance techniques with automated testing, and streamlining requirements management are core areas where AI is delivering value to DevOps today.”
AIOps toolset
AIOps tools consume data from various services. They collect application logs, measure system health or performance, ultimately breaking the siloed IT information problem and bridging between issues of software, hardware, and the cloud.
- Dynatrace – “The Dynatrace AIOps platform redefines performance monitoring allowing your teams to focus on proactive action, innovation, and better business outcomes.”
Dynatrace helps IT Operations with applications such as Root Cause Analysis, Event Correlation, and mapping to cloud environments to support continuous automation. Dynatrace functions can be categorized as below:
- Intelligent Observability – Advanced observability using contextual information, AI, and automation. Understand the full context of the issue and provide actionable answers after a precise root cause analysis.
- Continuous Automation – The manual effort of deploying, configuring, and managing is not worth it. Dynatrace proactively identifies the issues and determines their severity in terms of user and business impacts. It helps teams to achieve continuous discovery, effortless deployments, and automatic dependency mapping.
- AI-assistance – It performs fault-free analysis for root cause analysis. The Analysis is precise and reproducible. The AI engine is part of every aspect of Dynatrace.
- AppDynamics– “AppDynamics helps to Prioritize what’s most important to your business and your people so you can see, share and take action in real-time. Turn performance into profit with a deeper understanding of user and application behavior.”
It has different performance measure categories and helps in correlating these metrics from different categories to resolve issues before they can impact business. It’s used for AI-powered application performance management.
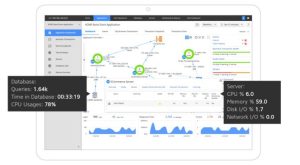
- User – Monitor key metrics across any device, browser, or third-party service to proactively identify end-user issues.
- Application – Unify IT teams and business by relating end-to-end observability of code affecting the KPIs that matters to the business.
- Infrastructure – It helps you to focus on the bottom line. Scale smarter through hybrid infrastructure and create a proactive infrastructure.
- Network – Monitor digital experience on any network. Users can correlate application performance with networks to identify application issues caused by network disruption.
- BMC Helix– “BMC solutions deploy machine learning and advanced analytics as part of a holistic monitoring, event management, capacity, and automation solution to deliver AIOps use cases that help IT Ops run at the speed that digital business demands.”
BMC Helix is a BMC product for Operations Management. It helps teams proactively improve the availability and performance of the system. Helix focuses on service monitoring, event management, and probable cause analysis.
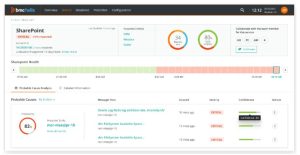
BMC products can help with orchestrated workflows for event remediation, Intelligent ticket resolution, automated change and incident management, and much more.
- Servicenow – Now Platform – “Now platform delivers cross-enterprise digital workflows that connect people, functions, and systems to accelerate innovation, increase agility, and enhance productivity.”
It helps teams to work faster and smarter by unleashing the power of AI. The core capabilities of the Now platform that enable efficient digitization of workflows are:
- Process Optimization – Now platform maximizes efficiency across enterprises by providing a clear picture of how each system is connected and impacts others. Once the issue is identified, it helps to refine the processes and monitor them.
- Performance Analytics – Look at the trends to identify bottlenecks before it occurs and improves the performance as and when required.
- Predictive Intelligence – While Now Platform uses machine learning to automate routine tasks and resolve issues faster, Team can focus on more meaningful work. Use ML to classify incidents, recommend solutions, and proactively flag any critical issues.
- IntegrationHub – IntegrationHub lets users integrate Now Platform with other ServiceNow services as well as out-of-the-box spokes. It helps to reduce integration costs and improve the productivity of the team.
- Virtual Agents – Now platform provides an AI-powered conversational chatbot to help teams and end-users resolve issues faster.
- AI Search – Use semantic search capabilities to provide precise and personalized answers.
- Configuration management database – Provide visibility into your IT environment to make better decisions. Connect products across the entire digital lifecycle to help teams understand impact and risk.
- IBM Watson AIOps – “Watson AIOps is an AIOps solution that deploys advanced, explainable AI across the ITOps toolchain so you can confidently assess, diagnose and resolve incidents across mission-critical workloads.”
Watson AIOps is trained to connect the dots across data sources and common IT industry tools in real-time. This helps in detecting and identifying issues quickly and transforming IT Operations with AIOps and ChatOps.
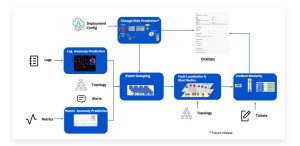
Watson AIOps takes a set of metrics, logs, and incident-related data for training and building unsupervised models. It’s a ChatOps; the models need to be trained continuously to improve the accuracy of problem-solving.
- Splunk – “Splunk is the only AIOps platform with end-to-end service monitoring, predictive management, and full-stack visibility across hybrid cloud environments.”
Splunk can help modernize your IT by – preventing downtime using predictive analytics, streamlining incident resolution, and correlating metrics from different services to identify the root cause.
Splunk’s innovations in domain-agnostic, service-centric AIOps give everyone in the Operations team the power to scale and the productivity to achieve faster remediation times.
MLOps vs AIOps
From the above explanations, it might be clear that these are two different domains and don’t overlap each other. Though, people often confuse MLOps and AIOps as one thing. When confused, remember:
- AIOps is a way to automate the system with the help of ML and Big Data,
- MLOps is a way to standardize the process of deploying ML systems and filling the gaps between teams, to give all project stakeholders more clarity.
Before we discuss the differences in detail, Let’s see an upfront comparison between MLOps and AIOps:
|
MLOps
|
AIOps
|
|
Standardizes ML system development process |
Automates IT operations and systems |
|
Increases efficiency and productivity of the team |
Automates root cause analysis and resolution |
|
Streamline collaboration between different teams |
Process and manage a large amount of data effectively and efficiently |
|
It is a crucial part of deploying AI and Data Science at scale and in a repeatable manner |
It leverages revolutionary AI technologies to solve IT challenges |
|
– Multi-source data consumptionrn– Source Code Controlrn– Deployment and Test Services-Tracking ML model using metadatarn– Automate ML experimentsrn– Mitigate risks and bias in model validation |
– Application Monitoring-Automating manual or repetitive processesrn– Anomaly Detectionrn– Predictive maintenancern– Incident management |
AI Ops, or “Artificial Intelligence for IT Operations” is the reverse of MLOps in one respect – it’s the application of ML to DevOps, rather than the application of DevOps to ML.
Let’s now have a look at different use cases and the benefits of implementing MLOps and AIOps.
Advantage of MLOps
As mentioned above, MLOps is focused on creating scalable ML systems. Let’s discuss how it’s different from the traditional way of developing ML Systems and why MLOps is important.
1. Orchestration of multiple pipelines
Machine learning model development is a combination of different pipelines (pre-processing, feature engineering model, model validation, etc). MLOps can help you orchestrate these pipelines to automatically update the model.
2. Managing ML Lifecycle
There are different steps of model development, and it can be challenging to manage and maintain using traditional DevOps. MLOps provides an edge to swiftly optimize and deploy ML models in production.
3. Scale ML Applications
The real issue arises when the data and usage increase, which can cause ML application failures. With MLOps, it’s possible to scale ML applications as and when demand increases.
4. Monitor ML systems
After deploying Machine learning models, it’s crucial to monitor the performance of the system. MLOps provide methods by enabling detection of model and data drifts.
5. Continuous Integration and Deployment
DevOps use continuous integration and deployment in software development but using the same is difficult when it comes to the development of ML systems. MLOps has introduced different tools and techniques where CI and CD can be leveraged to deploy machine learning systems successfully.
Real-life use cases of MLOps
- Web Analytics – Coinbase, AT&T
- Recommendation systems – OTT and Ecommerce platforms – A recommendation system that’s based on user behaviors while influencing these same behaviors. In this case, monitoring the predictions is essential to avoid a chain reaction.
- Share Market Analysis – Bloomberg
- Sports Analysis – ESPN, Sky Sports
Advantage of AIOps
AIOps has different use cases and benefits from MLOps as it leverages Machine learning techniques to improve IT Operations.
1. Proactive IT Operations
In a competitive environment, product and service success depends on customers’ satisfaction. Responding to an issue isn’t enough, but it’s crucial to predict if a failure will occur. It’s essential that IT Operations should be able to predict and remediate issues of applications, systems, and infrastructure.
2. Data-driven decision making
AIOps uses ML techniques in IT Operations e.g., Pattern Matching, Historical Data Analysis, and Predictive Analysis. With these ML techniques, the decisions will be purely data-driven and will reduce human error. Such automated response will allow IT operations to focus on resolution rather than detecting root cause.
3. Detecting anomalies and deviation from baseline
Using ML techniques like clustering, IT Operations can detect unusual behavior. AIOps helps in building these monitoring techniques that can be used in anomaly detection over network traffic and automatically modify firewall rules.
Real-life use cases of AIOps
- Predictive Alerting: Place Park Technologies and TDC NetDesign
- Avoiding Service Disruptions: Schaeffler Group
- Proper Monitoring of System: Enablis
- Blueprinting and Triaging of Incidents: PostNord AB
Conclusion
Throughout this article, we learned what MLOps and AIOps are, and how they can be used by companies to create effective, scalable, and sustainable systems. I hope you now understand the difference between these two, and where they can be used.
“While AIOps is used primarily to act on application data in real-time, MLOps tools monitor similar data for the purposes of building machine learning models. The tools can be used together for businesses that need both feature sets.” – Trust Radius
Thanks for reading, To learn more on how to implement AIOps & MLOps, Click Here to schedule a call with our experts.



