
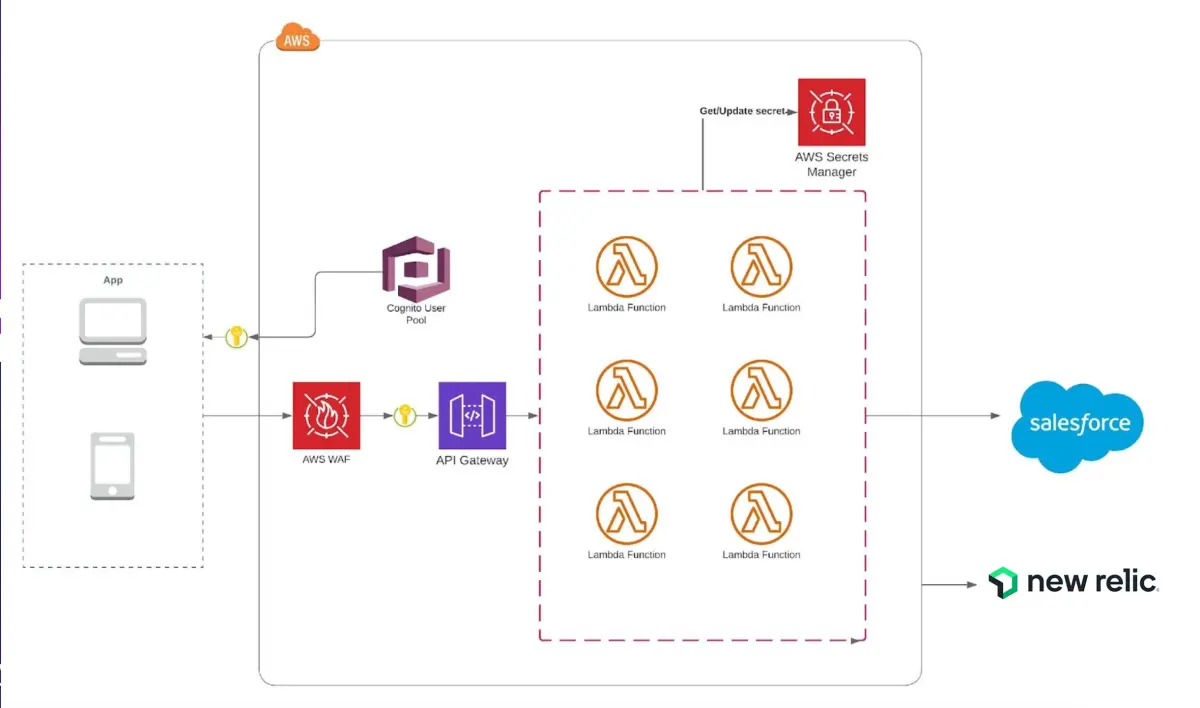
We wanted to integrate Salesforce customer data from our mobile and web applications across all of our operations. This is why we chose serverless. For example, if a customer purchases a policy, an event fires an AWS Lambda to send data to Salesforce to perform administrative tasks, like attaching a policy to the customer’s account. Then, our customer agents can then see this in a customer call in real time. This information can include policy purchase date, update, or cancellation, and much more. Our agents don’t need to solicit any of this information from the customer.
On the technical side, the customer application programming Interfaces (APIs) are available through the AWS API Gateway. We used the Serverless Framework to configure and deploy our architecture. In the serverless config file, we described endpoints and when to call AWS Lambdas. That also made it pretty easy to integrate with AWS WAF for security, AWS X-Ray for tracing, and AWS Lambdas to create the serverless functions.
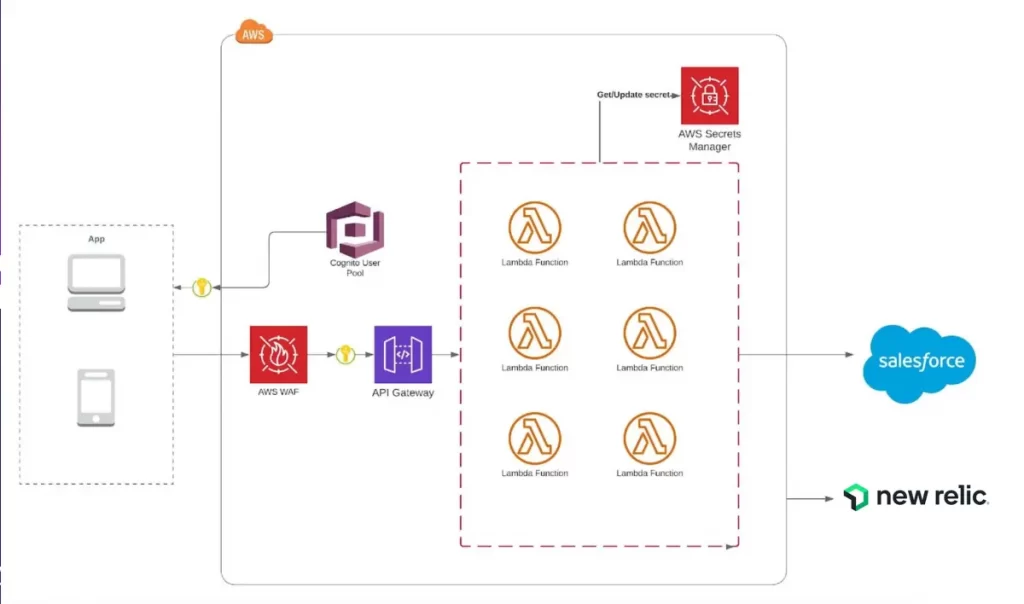
Monitoring serverless with dashboards
In serverless environments, you’re a step removed from the infrastructure. But you still need to see what is happening in your tech stack and how it affects your customers. We built dashboards to encourage a lean, agile culture. These dashboards focus on a small set of core metrics to help us understand customer experience and let our software engineering team drill down into issues as they arise. We also have retros every week where we discuss opportunities for continuous improvement. It’s a team approach. We share what worked to resolve challenges and we all learn from them. We discuss our infrastructure together and celebrate our progress as we climb towards our delivery goals.
To observe our serverless Lambdas, alongside metrics on our API gateway to monitor 500 errors, we use the New Relic Lambda function monitoring plugin. We built dashboards that show Lambdas and API calls in one place, alongside rejected requests. With the plugin, our engineers receive alerts in Slack and then reference the dashboard to drill down into specific Lambdas.
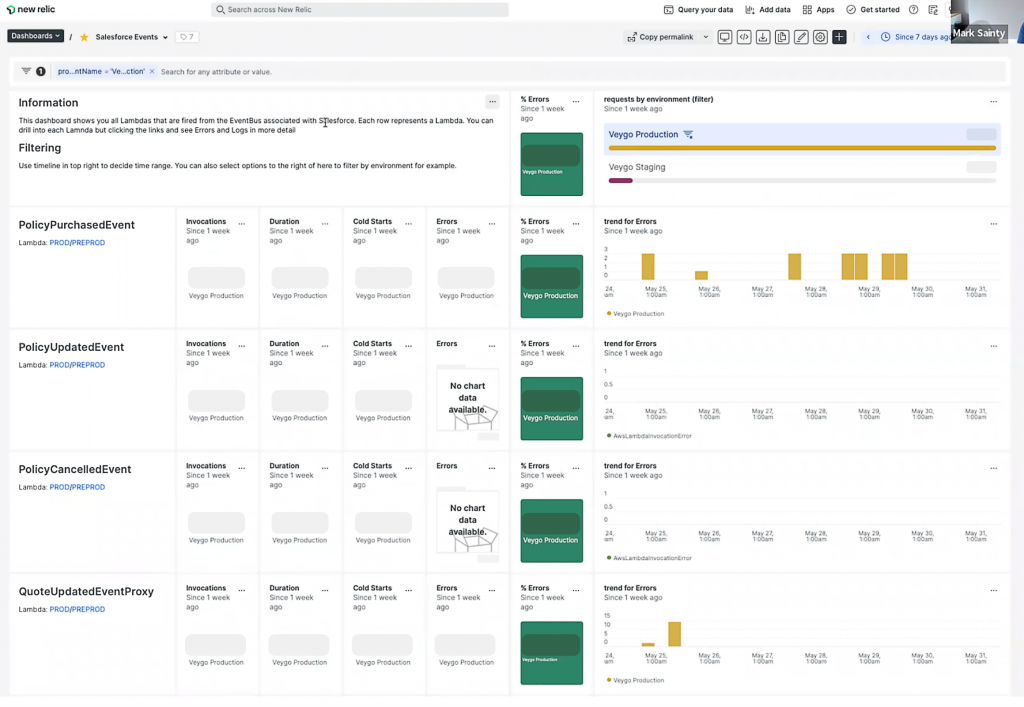
In our customer API dashboard, we display API endpoints, number of requests, and number of errors. If an alert is generated, you can see where the problem is. We’ve also got quick links on the dashboard that take you to the Lambda for a particular API endpoint. That also has the AWS Lambda metrics in New Relic that you can drill into. You’ve got logs as well. This is generally all you need to pinpoint any issues around your serverless APIs.
4 key metrics
Throughput
Measure: Deployment frequency
At the moment, we’re at about 140 releases a month, and we want to get to 200. All of our work is broken down into small tickets that we can advance through quickly. It’s a great way to work and it’s motivational to complete smaller tasks rather than one large task that can loom over the team. Completing these smaller tickets means the tickets get put into production sooner, and the team feels like we’re constantly delivering things.
We use a dashboard to keep us accountable. It shows the number of releases per day, week, and month. We also track the releases per app and how these releases trend. These dashboards are a pillar in our discussions on moving to 200 releases per month.
Measure: Lead time for change
Our lead time for change is from 10 minutes to 1 hour, depending on the application. We want to measure this to ensure any code committed will make it to production without delays. Improving the lead time has a positive impact on deployment frequency as engineers are not waiting too long before moving on to their next piece of work. It also has a positive impact on mean time to recovery (MTTR) as any change to fix an issue will also get to production quickly.
Stability
Measure: Change failure rate
With a high number of releases, an efficient delivery pipeline is a challenge. If you’re breaking everything down into smaller tasks, but your release takes two days to deploy—you’re not efficient.
Our main branch is in Git, which performs steps to push it to production. It’s running all your tests for you—doing all your checks, running integration tests, UI tests, and then deploying to production. This is where it is essential to have a quality metric. You need to make sure that your efficiency score isn’t sacrificing CI/CD pipeline agility by pushing through broken code that ends up stalling releases.
We are currently working on identifying the ideal quality metric internally. For now, we think this could be based on the amount of failed releases. For example, you might do 100 releases and you have to roll back two. You need both efficiency and quality metrics. If you just focus on the number of releases, you could release bad things all the time, with lots of failures. It’s important to have a balance between the two metrics.
Measure: MTTR
MTTR should be within an hour. We want to measure that and hold ourselves accountable to it. Visibility into recovery times helps the business decide if we want to pay for an additional supplier, which is an additional cost. The goal is to monitor MTTR so that we can make decisions that help us build resilient infrastructure.



